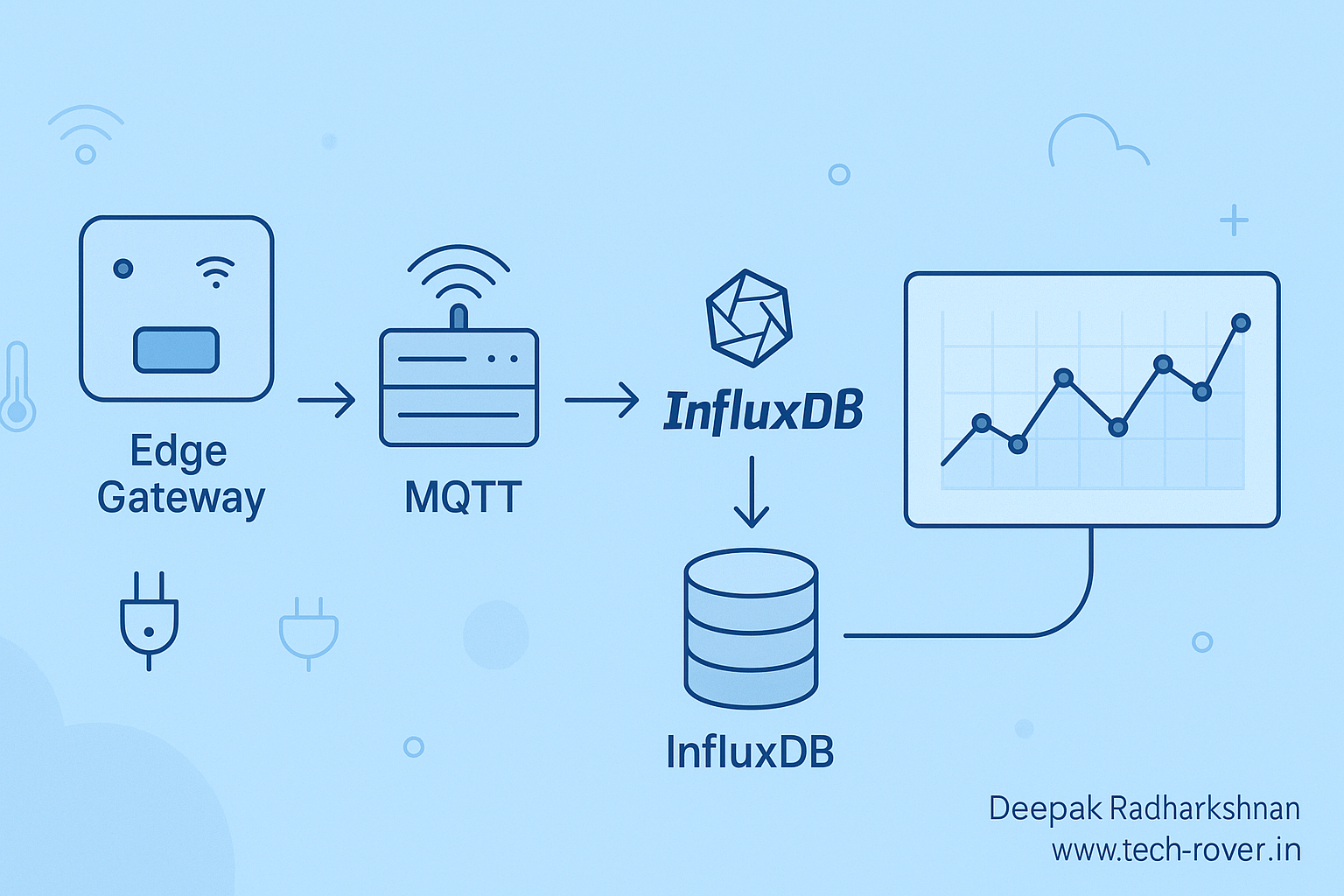
Introduction
If you’re building an IoT system, you’ll drown in data before you blink. Devices chatter nonstop; you need to ingest, store, query, and visualize—all with millisecond timestamps and unpredictable bursts. That’s exactly where InfluxDB shines. In this guide, we’ll build a clean mental model for using InfluxDB (especially v3) in IoT: from MQTT ingestion with Telegraf, to schema design that tames cardinality, to querying with SQL/InfluxQL, downsampling, and retention. I’ll show copy-pasteable configs and Python code that work with InfluxDB 3’s write and query paths so you can go from prototype to production without rewriting everything later. (InfluxData)
Why InfluxDB for IoT—now?
InfluxDB 3 swaps in a modern engine built in Rust on the FDAP stack—Apache Arrow Flight for fast columnar transport, DataFusion for SQL, and Parquet for durable storage. Translation: high-velocity ingest, cheap(-ish) long-term storage, and familiar query tooling. It also supports SQL and InfluxQL (Flux is now maintenance-mode and not supported in v3), which fits teams that want standards-ish querying without learning a whole new language. (InfluxData)
On the operations side, InfluxDB 3 product lines include Cloud and Enterprise/Clustered (self-managed), with decoupled ingest/query tiers for scale—useful when your sensors spike. (InfluxData)
Architecture at a glance (IoT)
Devices → MQTT → Telegraf → InfluxDB → Dashboard/Apps
- MQTT: low-overhead pub/sub transport many IoT devices already speak.
- Telegraf: a one-binary agent with 300+ plugins; it subscribes to MQTT topics, shapes messages, and writes to InfluxDB.
- InfluxDB 3: fast ingest via line protocol to
/api/v3/write_lp, compatibility endpoints for v2/v1 workloads, and query via FlightSQL (gRPC), SQL HTTP, or InfluxQL. (InfluxData)
Core concepts you’ll actually use
Measurements, tags, fields (schema)
- Measurement ≈ table name
- Tags = indexed, string-ish, good for metadata you filter/group by (device_id, site, model).
- Fields = values you aggregate (temperature, voltage, co2).
Keep measurements and keys simple and avoid “wide” schemas (too many columns) to prevent write/query pain. (docs.influxdata.com)
Pro tip: Device IDs as tags; sensor readings as fields. Plan schema from the queries you’ll run (dashboards, alerts, ML features). (InfluxData Community Forums)
Retention & downsampling
- In InfluxDB 3 Enterprise, you can set retention at database and table level, default is no expiry; choose the shortest practical horizon you need in hot storage. (docs.influxdata.com)
- Downsample high-rate data into coarser windows to cut storage and speed charts (historically via CQs/tasks; with v3 you can do this with SQL or external jobs/Telegraf aggregators). (docs.influxdata.com)
Hands-on: MQTT → Telegraf → InfluxDB 3
1) Telegraf: subscribe to MQTT and write to InfluxDB
Use the familiar v2 output (v3 supports v2-compatible /api/v2/write) so you don’t change Telegraf workflows. (docs.influxdata.com)
# telegraf.conf (minimal)[agent]
interval = “10s” flush_interval = “10s” # MQTT input: assumes JSON payloads like {“temp”: 21.7, “hum”: 36, “co”: 0} [[inputs.mqtt_consumer]] servers = [“tcp://mqtt-broker.local:1883”] topics = [“home/+/telemetry”] # wildcard for many devices data_format = “json” json_string_fields = [] # tag-like strings tag_keys = [“deviceId”,”room”] # promote these JSON keys to tags # Write to InfluxDB 3 using v2-compatible endpoint [[outputs.influxdb_v2]] urls = [“http://influxdb3.local:8086”] token = “$INFLUX_TOKEN” organization = “acme” # mapped internally bucket = “home” # maps to database in v3
Why this works: Telegraf’s MQTT consumer is built for exactly this flow, and InfluxDB 3 accepts v2-style writes as a compatibility path. (InfluxData)
Optional: If you control the writer, you can hit the native v3 /api/v3/write_lp endpoint directly with line protocol. (docs.influxdata.com)
2) Write directly via HTTP (v3 native)
curl -X POST "http://influxdb3.local:8181/api/v3/write_lp?db=home&precision=ns" \
-H "Authorization: Bearer $INFLUX_TOKEN" \
--data-raw 'home,room=Kitchen,deviceId=dev42 temp=21.7,hum=36i,co=0i 1730000000000000000'
The line protocol above writes one point with tags (room, deviceId) and fields (temp, hum, co). (docs.influxdata.com)
Querying in v3: SQL and InfluxQL side-by-side
Option A: Python + FlightSQL (fast, columnar)
# pip install influxdb3-python pyarrow
from influxdb_client_3 import InfluxDBClient3
client = InfluxDBClient3(
host="influxdb3.local",
token="YOUR_TOKEN",
database="home",
)
# Average kitchen temperature by 1-minute bins for last day (SQL)
sql = """
SELECT
date_bin(INTERVAL '1 minute', time) AS window_start,
AVG(temp) AS avg_temp
FROM home
WHERE room = 'Kitchen' AND time >= now() - INTERVAL '1 day'
GROUP BY window_start
ORDER BY window_start
"""
df = client.query(sql) # returns a PyArrow Table / pandas-friendly
print(df.to_pandas().head())
This uses FlightSQL under the hood and the date_bin helper for time windows. (docs.influxdata.com)
Option B: InfluxQL (familiar to 1.x users)
-- 1-minute mean using InfluxQL
SELECT MEAN(temp)
FROM home
WHERE room = 'Kitchen' AND time >= now() - 1d
GROUP BY time(1m) fill(none)
InfluxDB 3 supports InfluxQL and SQL—handy during migrations. (docs.influxdata.com)
Heads-up: Flux is maintenance-mode and not supported in v3. For future-proofing, target SQL or InfluxQL. (docs.influxdata.com)
Practical example: A “smart greenhouse” pipeline
Goal: Monitor temp/humidity/CO₂ from dozens of greenhouses, alert on spikes, and show daily trends.
- Schema
- Measurement:
greenhouse - Tags:
site,zone,deviceId - Fields:
temp,hum,co2,vbat
Keep it narrow and query-driven to avoid wide tables and exploding cardinality. (docs.influxdata.com)
- Measurement:
- Ingest
- Devices publish JSON to
gh/<site>/<zone>/telemetry. - Telegraf subscribes and writes to database
greenhouse(v2-compat write). (InfluxData)
- Devices publish JSON to
- Downsampling
- Keep raw at 10s resolution for 7 days; aggregate to 1-minute and 15-minute rollups for 90 days.
- Implement with a scheduled SQL job (or Telegraf aggregators) that writes results into
greenhouse_rollup_1m/_15m. (docs.influxdata.com)
- Retention
- Set database retention to 7d for
greenhouse_raw, 90d for rollups (Enterprise supports database/table retention; default is infinite). (docs.influxdata.com)
- Set database retention to 7d for
- Dashboards/Apps
- Query FlightSQL from your app for responsive charts; group with
date_bin()in SQL. (docs.influxdata.com)
- Query FlightSQL from your app for responsive charts; group with
Advanced techniques & performance tips
- Batch writes: send points in batches (~10k lines or ~10 MB per batch) to cut overhead. Telegraf’s
metric_batch_sizeandflush_intervalcontrol this automatically. (docs.influxdata.com) - Edge replication: capture data at the edge and replicate upstream with a durable queue when the link returns—great for intermittent networks. (InfluxData)
- Compatibility paths: migrating from 1.x/2.x? Use
/write(v1) or/api/v2/write(v2) while you port queries to SQL/InfluxQL. (docs.influxdata.com) - Pick the right query path: FlightSQL (gRPC) is fastest for analytics; HTTP SQL is simple for services; InfluxQL is perfect for legacy dashboards. (docs.influxdata.com)
Common pitfalls (and how to avoid them)
- Over-tagging every attribute → High cardinality and slow queries. Only tag what you filter/group by; keep the rest as fields. (docs.influxdata.com)
- Too-wide tables → write/compaction cost rises. Split into a few logical measurements if you’re pushing lots of columns. (docs.influxdata.com)
- Relying on Flux in new builds → v3 doesn’t support it; use SQL/InfluxQL. (docs.influxdata.com)
- Skipping downsampling → dashboards get sluggish as data grows; schedule rollups early. (InfluxData)
Conclusion
InfluxDB remains a top pick for IoT: simple line protocol ingest, a battle-tested agent in Telegraf, and—with v3—fast SQL/InfluxQL queries over an Arrow/Parquet core. If you design your schema around queries, batch your writes, and plan retention/downsampling from day one, you’ll scale gracefully from a handful of sensors to fleets.
Key takeaways
- Use Telegraf + MQTT for painless ingest. (InfluxData)
- Target SQL or InfluxQL (not Flux) for v3. (docs.influxdata.com)
- Batch writes and downsample early. (docs.influxdata.com)
- Configure retention per database/table (Enterprise). (docs.influxdata.com)
What’s your device footprint and target data rates? I can tailor a concrete config (batch sizes, topic layout, retention) for your setup.



Leave a Reply